序言
因近期所做项目需要用到CV-CNN进行图像识别分类,广泛查阅网络上各大博客,特作此博客用以总结。本文中部分资料摘自: CNN初学者——从这入门
历史趣闻
二十世纪四十年代 M-P 神经元模型、Hebb 学习律出现后,五十年代出现了以感知机、Adaline 为代表的一系列成果。后来因为单层神经网络无法解决非线性问题,而多层网络的训练算法尚看不到希望,神经网络研究进入“冰河期”。哈佛大学的 Paul Werbos 在 1974 年发明 BP 算法时,正值“冰河期”,因此未受到重视。
1983 年,物理学家 John Hopfield 利用神经网络,在旅行商问题这个 NP 完全问题的求解上获得了当时最好的结果,引起轰动。稍后,UCSD 的 Rumelhart 等人重新发明了 BP 算法,再次掀起研究神经网络的热潮。二十世纪九十年代中期,随着统计学习理论和支持向量机的兴起,神经网络学习的理论性质不够清楚、试错性强、在使用中充斥大量“窍门”的弱点更为明显,于是神经网络的研究又进入低谷。
2010 年前后,随着计算能力的迅猛提升和大数据的涌现,神经网络研究在“深度学习”的名义下又重新崛起,先是在 ImageNet 等若干竞赛上以大优势夺冠,此后谷歌、百度、脸书等公司纷纷投入巨资进行研发,神经网络迎来第三次高潮。
1 CNN概述
CNN——Convolutional Neural Networks,即卷积神经网络,是一类包含卷积计算且具有深度结构的前馈神经网络,属于人工神经网络(ANN)的一种分支,也是深度学习的代表算法之一,主要应用于CV(Computer Vision,计算机视觉)和NLP(Natural Language【自然地随文化演化的语言,如英语,汉语】 Process,自然语言处理)。
2 相关概念注释
若是初次接触CNN这一概念,则一定会像笔者最初一样,在前文的CNN概述中有很多不懂的名词,下面将对这些专业概念一一细细讲解,可选择性阅读。
2.1 人工神经网络
人工神经网络,即Artificial Neural Network,缩写为ANN,其权威定义为:
由大量的处理单元(神经元) 互相连接而形成的复杂网络结构,是对人脑组织结构和运行机制的某种抽象、简化和模拟;以数学模型模拟神经元活动,是基于模仿大脑神经网络结构和功能而建立的一种信息处理系统。
ANN模型常被分为三大类:前馈型网络(feed-forward network)、反馈型网络(feedback network)、竞争学习型网络(competitive learning network)。故包含关系为ANN>FFN>MLP>CNN>LeNet,AlexNet。
2.2 前馈神经网络
定义:
-
各神经元分层排列,且每个神经元只与前一层的神经元相连。
-
只接收前一层的输出,并输出给下一层.各层间没有反馈。
前馈神经网络是目前结构最简单,应用最广泛、发展最迅速的人工神经网络之一。所谓的“前馈”也即每层神经元之间只存在和前(后)一层的输入-输出关系。
常见的前馈神经网络包括(多层)感知器网络(主要用于模式分类),BP(Back Propagation)网络,RBF网络等;而本文主角CNN便属于多层感知器网络的一种分支。
3 CNN网络结构
如上文所述,卷积神经网络沿用了普通神经元网络结构,以应用于图像领域的CNN为例,大致结构如下图。 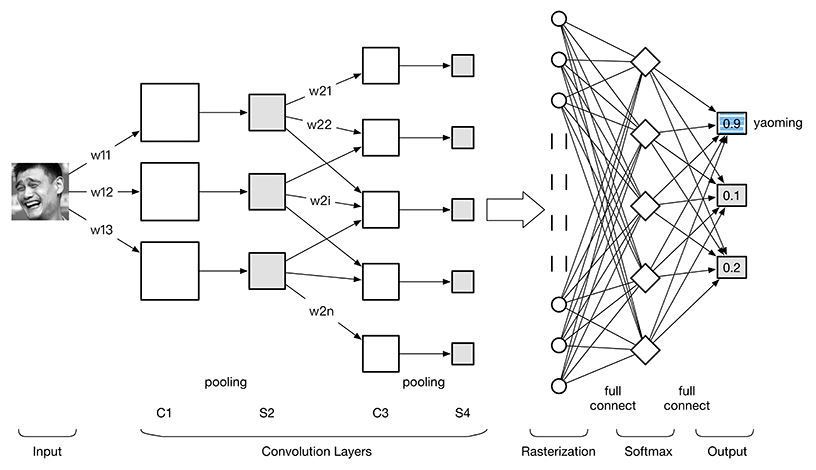 根据上图,ConveNet可分为四部分:
根据上图,ConveNet可分为四部分:
-
图像输入Image Input:为了减小后续BP算法处理的复杂度,一般建议使用灰度图像。也可以使用RGB彩色图像,此时输入图像原始图像的RGB三通道。对于输入的图像像素分量为 [0, 255],为了计算方便常需要归一化,如果使用sigmoid激活函数,则归一化到[0, 1],如果使用tanh激活函数,则归一化到[-1, 1]。
-
卷积层Convolution Layer:特征提取层(C层) & 特征映射层(S层)。将上一层的输出图像与本层卷积核(权重参数w)加权值,加偏置参数,通过一个Sigmoid函数得到各个C层,然后下采样subsampling(也被称为池化,pooling)得到各个S层。C层和S层的输出称为Feature Map(特征图)。
-
光栅化(Rasterization):为了与传统的多层感知器MLP全连接,把上一层的所有Feature Map的每个像素依次展开,排成一列。
-
多层感知器(MLP):也即分类器,一般使用Softmax(多分类),如果是二分类,当然也可以使用Logistic Regression,SVM,RBM等。
3.1 卷积 Convolution
对图像(处理过产生的窗口数据)和滤波矩阵(也被称为滤波器,filter)做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作。下面的动图可完美地解释:

3.2 池化 Pooling
在卷积神经网络中,并非一定要对原图像做处理,而是可以使用某种“压缩”方法,这就是池化,也就是每次将原图像卷积后,都通过一个下采样的过程,来减小图像的规模。
一句话,池化=压缩。
pooling的好处有什么?
- 这些统计特征能够有更低的维度,减少计算量。
- 不容易过拟合,当参数过多的时候很容易造成过度拟合。
- 缩小图像的规模,提升计算速度。
如下图所示,原图是一张500∗500 的图像,经过subsampling之后就变成了一张 250∗250 的图像。这样操作的好处非常明显,在可接受范围内牺牲一定的准确率的情况下大幅减少计算量,这一点绝对是CNN得以广泛应用乃至CV兴起的重要原因。
举例,以最大池化(Max Pooling)为例,1000×1000的图像经过10×10的卷积核卷积后,得到的是991×991的特征图,然后使用2×2池化规模的最大池化算法,最终得到的是496×496大小的特征图。
此外,池化规模通常2×2,常用的池化算法有以下几种:
- 最大池化(Max Pooling),取4个点的最大值。
- 均值池化(Mean Pooling),取4个点的平均值。
- 可训练池化,训练函数f,接受4个点的输入,输出一个点。
另由于特征图的边长不一定是2的倍数,对应的边缘处理问题常有以下两种方案。
- 保留边缘,将特征图的边长用0填充为2的倍数后再进行池化。
- 忽略边缘,将多出的边缘一刀切掉。
3.3 CNN核心思想
卷积神经网络CNN的出现是为了解决MLP多层感知器全连接和梯度发散的问题。其引入三个核心思想:1.局部感知(local field),2.权值共享(Shared Weights),3.下采样/池化(subsampling/pooling)。减少了神经元输入的连接数量,极大地提升了计算速度。
在上文中已解释过池化的原理,在此不再赘述。
3.3.1 局部感知
局部感知是卷积操作的核心理念。
形象地说,就是模仿人的眼睛,当人在看东西的时候,目光是聚焦在一个相对很小的局部的吧。严格一些说,普通的多层感知器中,隐层节点会全连接到一个图像的每个像素点上,而在卷积神经网络中,每个隐层节点只连接到图像某个足够小局部的像素点上,从而大大减少需要训练的权值参数。
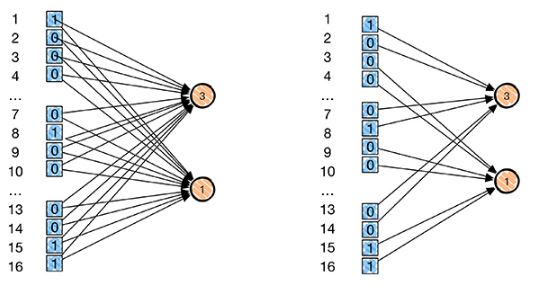
对于一个 1000∗1000 的输入图像而言,如果下一个隐藏层的神经元数目为 10 个,采用全连接则有 1000∗1000∗106=1012个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中 10∗10的局部图像相连接,那么此时的权值参数数量为 10∗10∗106=108,将直接减少4个数量级。
如下图所示,左边是每个像素的全连接,右边是每行隔两个像素作为局部连接,因此在数量上,少了很多权值参数数量(每一条连接每一条线需要有一个权值参数,具体忘记了的可以回顾单个神经元模型。因此 局部感知就是:
通过卷积操作,把全连接变成局部连接,因为多层网络能够抽取高阶统计特性,即使网络为局部连接,由于格外的突触连接和额外的神经交互作用,也可以使网络在不十分严格的意义下获得一个全局关系。
3.3.2 权值共享
不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权值参数。
如下图所示,为了找到鸟嘴,一个激活函数A需要检测图像左侧有没有鸟嘴,另外一个激活函数B需要检测另外一张图像中间有没有类似的鸟嘴。其实,鸟嘴都可能具有同样的特征,只需要一个激活函数C就可以了,这个时候,就可以共享同样的权值参数(也就是卷积核)。
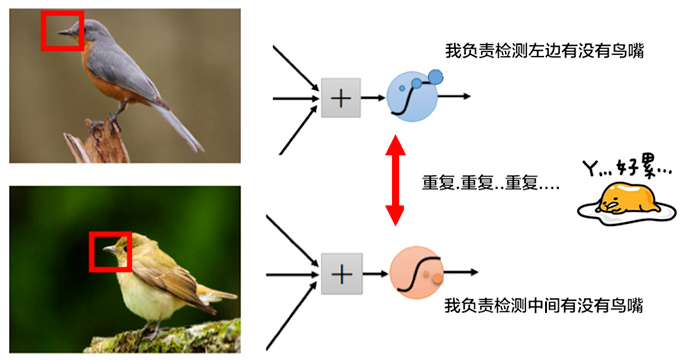
如果使用了权值共享(共同使用一个卷积核),那么将可以大大减少卷积核的数量,加快运算速度。
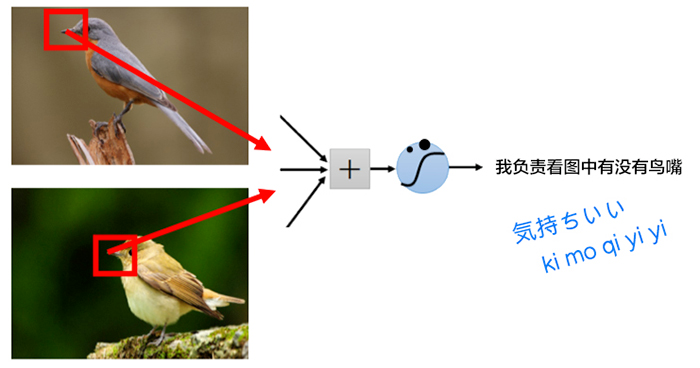
举个栗子,在局部连接中隐藏层的每一个神经元连接的是一个 10∗10 的局部图像,因此有 10∗10 个权值参数,将这 10∗10 个权值参数共享给剩下的神经元,也就是说隐藏层中 106 个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10∗10 个权值参数(也就是卷积核(也称滤波器)的大小。
尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,需要增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为 Feature Map。如果有100个卷积核,最终的权值参数也仅为 100∗100=104 个而已。另外,偏置参数b也是共享的,同一种滤波器共享一个。
总结回顾
CNN处理过程
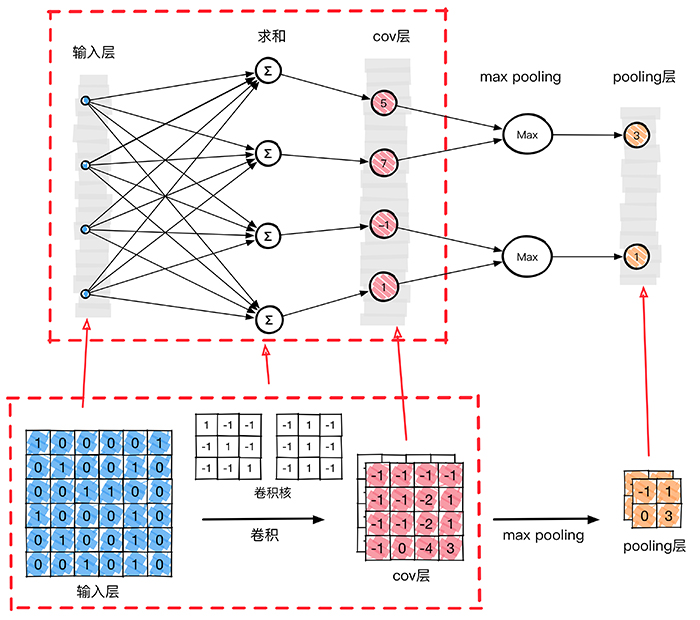
原始图像–>C层:需要把原始图像中的每一个像素值作为神经网络当中一个神经元,把原始输入图像一字排开,作为输入层。通过BP反向传播算法计算好的,或是从图中随机取的权值参数(卷积核)去计算C层对应的的每一个像素的值。
C层–>S层:进一步抽取高层特性,因此需要进步特征映射层(S层)。下图的pooling层(S层)使用了max pooling算法,pooling核为2x2,没有重叠部分,取每4个像素中最大的一个像素值作为新的像素值。
在这个模型当中,我们已经确定了激活函数φ(∗),输入x1,x2,…,xn 是确定的,未知量就剩下神经元k的突触权值wk1,wk2,…,wkn和bk 偏置。反向传播-BP算法(back propagation)就是为了求整个神经网络当中的两种未知变量:权值 w 和偏置 b。在上图这个模型当中,卷积核大小为3∗3,也就是有9个权值w组成,因此反向传播的时候就是要求这两个卷积核的权值w,使用大量的图片作为输入就是为了使用BP算法求得最佳的卷积核的值,当求得卷积核的值之后,分类的时候输入一张未知的图片,然后通过整个网络,直接就可以得到最终的分类结果,因为权值和偏置已经通过训练求出来了,整个网络没有未知量。
概念小结
卷积神经网络CNN的核心思想是:局部感知(local field),权值共享(Shared Weights)以及下采样(subsampling)这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性,提高了运算速度和精度。
多层网络可以根据其输入引出高阶统计特性, 即使网络为局部连接,由于格外的突触连接和额外的神经交互作用,也可以使网络在不十分严格的意义下获得一个全局关系。这也就是CNN使用局部连接之后还获得很好的效果的原因。